Testing in Production
The vast majority of tests focus on pre-production validation, specifically using tests to ensure that the software is of sufficient quality before deploying it into production. Test outcomes influence the decision on whether our software should be deployed.
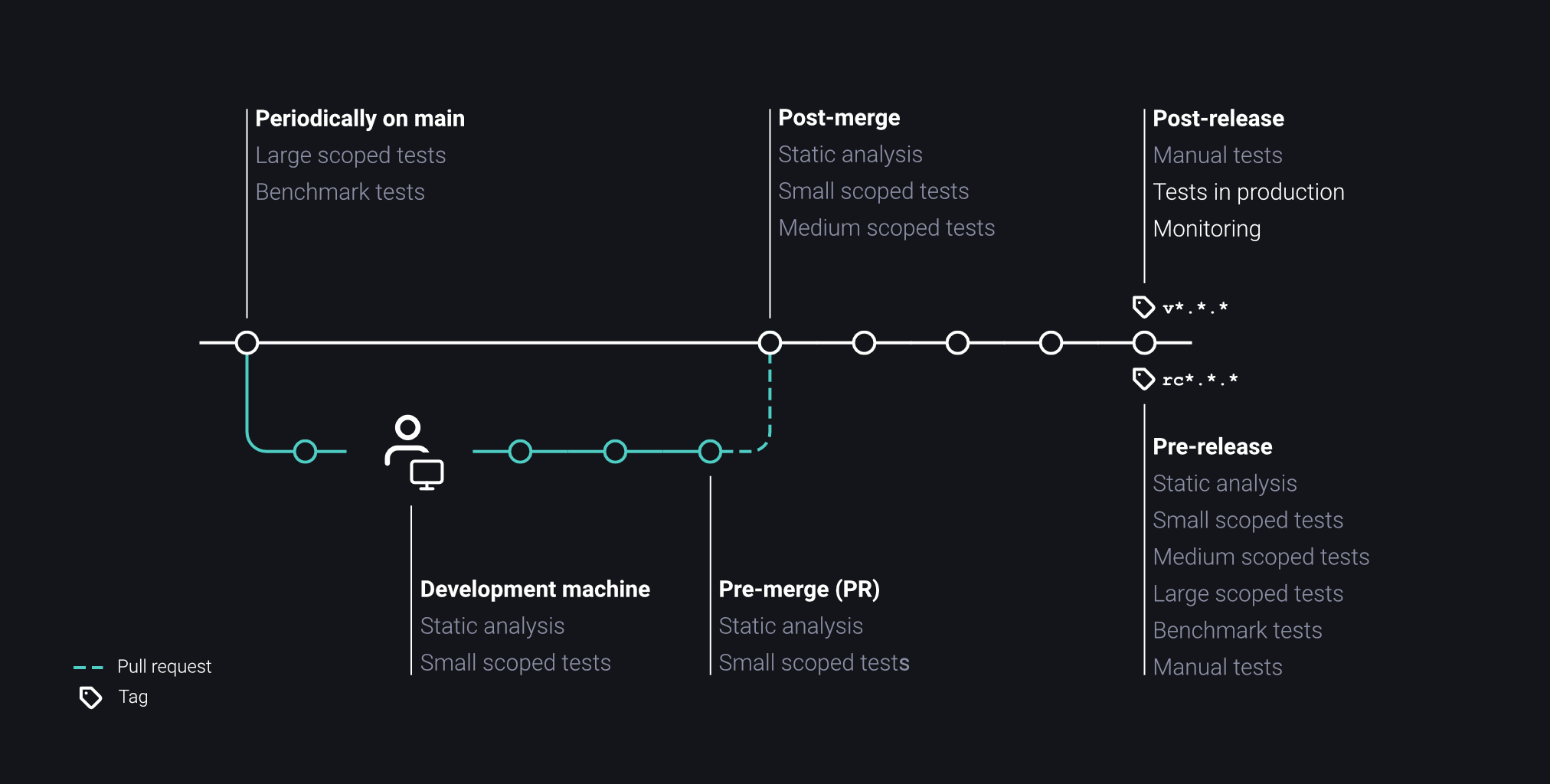
Alas, testing does not end once our software is in production. It would be embarrassing for our company if we were the last to know whether our live software is running or not. We do not rely on bug reports from our user base to be made aware of active problems. Since our production deployment varies from our test environment, we either test in production or live a lie.
Incremental Rollouts
When releasing new versions, we roll out our changes to the public in iterations. Blue-green deployments and canary releases appraise working functionality and evaluate product decisions with a subset of our user base before fully committing to distributing changes. We cover these procedures in detail in Release Strategies (*WIP).
Production Systems
A live system used by a high number of users functions differently than our internal test environment. Our system copes with a higher amount of users, requests, bots, noise, and infrastructure dependencies.
Aspects of our systems need to be verified in production to assess real-world functionality. We monitor and evaluate caching and cache invalidation, token timeouts, availability across zones, and other metrics indicative of performance and system health.
As we do not have full control over our third-party integrations and partner contracts, these may solely be effectively tested continuously in live environments. We certify working anchors, referral links, and third-party modules periodically to maintain agreements with partner entities and proactively provide feedback in case of outages.
Registering fake users, our manual and automated tests perform tasks to verify expected outcomes of LSTs within the noisy live environments. Utilizing this pool of fake users, the product and quality departments uncover unexpected or opaque behavior for varying user groups.
Chaos Engineering
If not pioneered by Netflix, chaos engineering is certainly being spearheaded by the streaming service. It is a practice of purposefully wrecking services in our live production software. As Netflix reached a global scale of constant availability, the chance of outages across a worldwide system reaches certainty. Natural disasters, political interference, limitations of celestial mechanics combined with a global IT infrastructure that only just works constrain the workings of our offering.
By introducing Chaos Monkey, a tool wreaking havoc on production systems, the mindset of engineers switched from services might fail to services will be killed. This practice leads to more robust systems as potential fragility (like network timeouts) is elevated from an outlier to being the norm. When outages do happen, the system and its services are designed to cope.