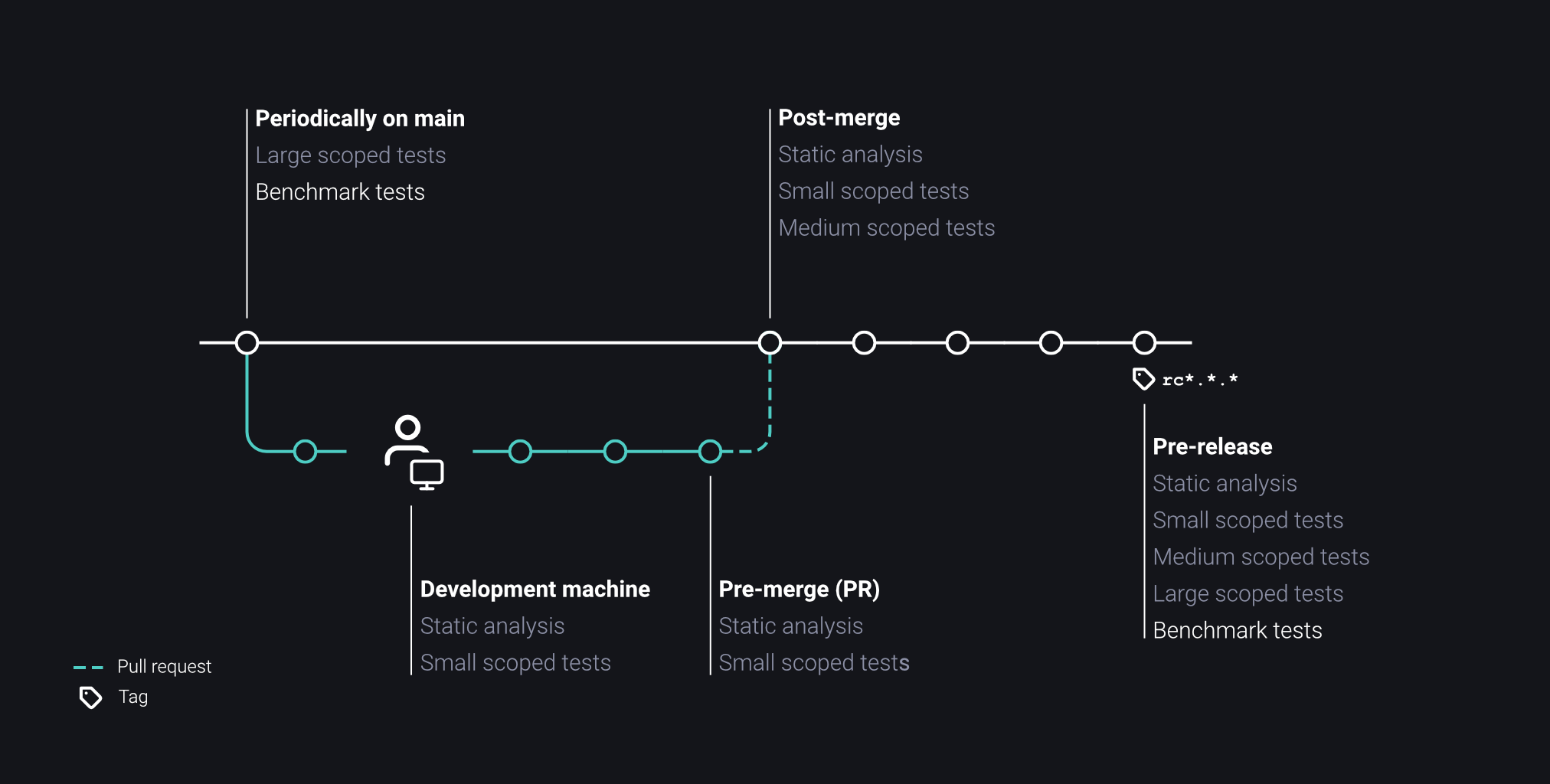
Benchmark Tests
When releasing new versions of our software, our acceptance criteria exceed operational functionality and stability. In order to avoid any kind of performance regression, we run our changes through relevant benchmark tests. As the word benchmark indicates, these tests check for discrete metrics for a certain facet of our software. The evaluated benchmarks of our software indicate whether our organization meets the acceptance criteria of stakeholders and compare our performance to competitors on the market.
Performance Tests
Testing against performance identifies efficiency bottlenecks within our software and, if done over time, helps us avoid introducing performance regressions with our changes. We define performance as any metric occurring during runtime that we care about and decide to document.
For example, we identify issues related to memory leaks and resource management by running our software at full capacity for an extended amount of time. We measure the system's maximum load and user interactions by continuously incrementing the amount of concurrent calls until processing errors crop up. We measure the acceptable loading time of a web page and response times for user interactions to ensure our system meets acceptable latency standards.
We may measure performance-increasing strategies of cache effectiveness, edge content delivery, lazy loading, deferred executions, or whatever else we identify as crucial for our use cases.
Robustness Tests
While performance tests evaluate our proficiency when everything goes well, robustness tests assess our capacity for dealing with increased load and failures.
We evaluate our system's ability to adapt to traffic spikes and increased resource requirements by scaling up or down in terms of hardware, software, or network resources. We test our system's conduct under extreme conditions or beyond its expected maximum capacity, pinpointing the stress our software handles before breaking. When things break, we want them to break well-defined and with immediacy. Non-determinism and unknown states in our software are hazardous things.
After the worst has happened and our software crashed either due to a lack of scalability or malicious third-party attacks, we test our disaster recovery measures. Shorter durations to fully recover from downtime minimize potential costs and revenue losses to our organization.
Accessibility Tests
We maximize the number of potential users by making certain our software is usable by a broad spectrum of people. Traditionally, accessibility was related to physical traits, such as vision, mobility and motor skills, hearing, speech, or cognitive disabilities. Depending on our product, we utilize a mix of static and runtime tests to verify perceptibility and input options for various senses to interact with our software. We test for contrasting color palettes, labeling, navigation, text-to-speech, font size and content zooming, and inspect our UIs and APIs against our design system to ensure internal consistency within the software.
We extend physical accessibility traits with demographic, economical, and geographic factors. We test whether our software runs on a broad range of devices, potential outdated hardware, and with low-bandwidth internet. Our payment options and processing work beyond US credit cards, our application layout adapts for reading both left-to-right and right-to-left, our software uses culturally invariant upper-case and lower-case characters when processing input text and we support a broad range of character encoding.
If our distribution location requires regulatory compliance, we appraise those when releasing changes to our software. We test against these requirements when packaging localized versions of our package.
Executing Benchmark Tests
We run benchmark tests multiple times a week during low-traffic hours during the week or on the weekend. The longer we go without running performance tests, the harder it can be to track down the culprit.